КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Аккумулирование заключений нечетких правил
|
|
|
|
Аккумулирование заключений нечетких правил в системах нечеткого вывода представляет собой нахождение функции принадлежности для каждой из выходных лингвистических переменных множества W ={w1, w2,..., w s }.
Целью аккумулирования является объединение всех степеней истинности заключений для получения функции принадлежности каждой из выходных переменных. Необходимость выполнения этого этапа обусловлена тем, что подзаключения, относящиеся к одной и той же выходной лингвистической переменной, принадлежат различным правилам системы нечеткого вывода.
Аккумулирование выполняется следующим образом. Предварительно предполагаются известными значения истинности всех подзаключений для каждого из правил Rk, входящих в рассматриваемую базу правил P системы нечеткого вывода, в форме совокупности нечетких множеств: С1, С2,…, С q, где q — общее количество подзаключений в базе правил. Далее последовательно рассматривается каждая из выходных лингвистических переменных w j Î W и относящиеся к ней нечеткие множества: С j 1, С j 2,…, С jq. Результат аккумуляции для выходной лингвистической переменной w j определяется как объединение нечетких множеств С j 1, С j 2,…, С jq по одной из формул:
r max-объединение двух нечетких множеств A и B (1.4):
m D(x)= max{mA(x),mB(x)} (" x Î X).
r алгебраическая сумма:
m D(x)= mA(x)+mB(x)- mA(x)mB(x), (" x Î X). (2.8)
r граничная сумма:
m D(x)= min{mA(x)+mB(x), 1} (" x Î X). (2.9)
r драстическая сумма:
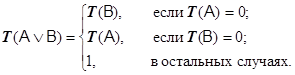
| (2.10) |
r l-сумма:
m D(x)= l mA(x)+(1-l)mB(x) (" x Î X), lÎ[0, 1]. (2.11)
Этап аккумуляции завершается, когда для каждой из выходных лингвистических переменных будут определены итоговые функции принадлежности нечетких множеств их значений, т. е. совокупность нечетких множеств: С1¢, С2¢,…, С s ¢, где s — общее количество выходных лингвистических переменных в базе правил системы нечеткого вывода.
Пример. Рассмотрим аккумулирование заключений для двух нечетких множеств С11 и С12, полученных в результате выполнения активизации для выходной лингвистической переменной " скорость автомобиля ". Пусть функции принадлежности этих нечетких множеств имеют вид как показано на рис. 2.6, а, б соответственно.
Аккумулирование этих функций принадлежности методом max-объединения нечетких множеств С11 и С12 по формуле (1.4) позволяет получить в результате функцию принадлежности выходной лингвистической переменной " скорость автомобиля ", которая представлена на рис. 2.6, в. Эта функция принадлежности соответствует нечеткому множеству С1¢, если принять, что рассматриваемая выходная лингвистическая переменная есть w1.
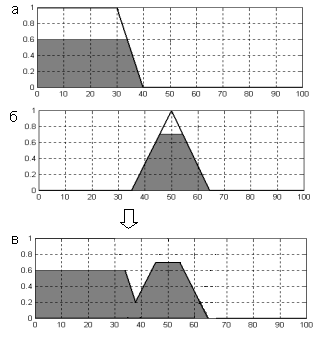
Рис. 2.6. Аккумулирование заключения с использованием max-объединения
Кроме указанных методов для аккумулирования могут использоваться и другие способы, основанные на модификации различных операций объединения нечетких множеств.
|
|
|
|
|
Дата добавления: 2017-02-01; Просмотров: 143; Нарушение авторских прав?; Мы поможем в написании вашей работы!