КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Метод монте-карло
|
|
|
|
Имитационное моделирование используется в случаях, когда применение математических аналитических моделей неадекватно или является слишком сложным. Хотя методы имитационного моделирования не слишком элегантны, они являются очень гибкими и мощными в применении. Они шаг за шагом воспроизводят процесс функционирования системы. Эта система может включать ряд стохастических переменных. В системе управления запасами, например, неопределенности могут быть подвержены как ежегодный спрос, так и срок реализации заказа.
Используя выборочные данные, можно моделировать поведение системы. Если имитационное моделирование применяется в течение достаточно длительного периода, появляется возможность создавать модели с периодическим циклом или рассчитывать математические ожидания для определенных параметров. Имитационное моделирование может помочь при составлении прогнозов.
Одним из методов имитационного моделирования является методМонте-Карло. В данном методе всем переменным присваиваются дискретные значения, даже если на самом деле эти переменные являются непрерывными. Переменная времени, например, может подразделяться на интервалы в минутах, часах или днях в зависимости от моделируемой системы. Затем рассчитываются вероятности каждого значения.
В имитационном моделировании, рассмотренном нами ранее, при построении моделей и их последующем анализе, как правило, широко используются компьютеры. В этой области применение компьютеров становится особенно важным, поскольку значимую и обоснованную информацию из имитационной модели можно получить только после проведения расчетов для различных случайных чисел.
Принципы построения дискретных имитационных моделей
В основу исследований рынка положена предпосылка о том, что клиент пытается выработать оценку общественного мнения по интересующему его вопросу. Клиент желает знать, какова продолжительность определенной работы и ее стоимость. Первый этап заключается в организации выборочного обследования и разработке анкеты. Вторым этапом является сбор исходных данных. Предположим, что подготовлена соответствующая анкета и выработан план проведения выборочного обследования. Пусть принято решение, что сбор информации будет проводиться интервьюерами путем опроса прохожих на улицах крупного города. Длительность проведения обследования и соответствующие затраты зависят от того, сколько времени понадобится интервьюеру для сбора исходных данных. Каким образом ответственная за проведение обследования организация может оценить, сколько времени потребуется для его проведения?
Необходимо провести анализ ситуации [68]. Интервьюеру придется останавливать прохожих, спрашивать об их желании или нежелании дать интервью, и в случае, если они согласны, задать им соответствующие вопросы. Переменными в данной ситуации являются следующие величины:
1. Интервьюеру придется ожидать прохожего, которого можно остановить. Следовательно, нам необходимо знать величину интервала между последовательными моментами появления прохожих (IAT).
2. Желание прохожего дать интервью.
3. Продолжительность самого интервью.
Если нам удастся сгенерировать информацию, отражающую процесс остановки прохожего и его возможное интервьюирование, то мы сможем построить имитационную модель для данной проблемы и оценить время, требующееся для того, чтобы набрать необходимое число интервью. Причем данные должны отражать стандартные характеристики переменных, которые были идентифицированы выше. Каждая из этих переменных является стохастической, т.е. подверженной неопределенности. Наиболее простой способ состоит в сборе определенных данных через проведение испытаний.
Если в качестве испытания выбрать поток из 100 прохожих, то можно зафиксировать временные интервалы между их последовательным появлением, желание или нежелание быть проинтервьюированным и, если они дадут согласие, — продолжительность интервью. Степень точности этих данных зависит от специфики проблемы. В данном случае совершенно неважно, чтобы время было зафиксировано с высокой степенью точности. Кстати, именно на этой стадии принимается решение о том, какие дискретные значения времени следует использовать. Например, между последовательным появлением двух прохожих проходит приблизительно 1 мин., а каждое интервью занимает примерно 2 мин.
После того как собраны данные для потока из 100 прохожих, для каждой переменной можно построить распределение частот и рассчитать соответствующее значение вероятности. Предположим, что по результатам испытания были зафиксированы следующие данные:
Таблица 8.7
Модель появления прохожих — интервалы
между моментами появления
| Время между | ||||||
| появлениями прохожих | / | 2 | 3 | 4 | 5 | |
| около интервьюера, | ||||||
| мин. | ||||||
| Число появлений, f | ||||||
| Вероятность (f - 100) | 0,25 | 0,35 | 0,18 | 0,10 | 0,08 | 0,04 |
Из общего числа опрошенных 75 человек выразили желание дать интервью. Следовательно, вероятность того, что некоторый прохожий будет согласен на интервью, можно оценить как 0,75.
Таблица 8.8
Продолжительность интервью
| Продолжительность интервью, мин | 2 | 4 | |
| Количество интервью, f | |||
| Вероятность (f + 100) | 0,40 | 0,45 | 0,15 |
Как эти данные можно использовать, для того чтобы сгенерировать процесс появления прохожих? Один из методов генерирования — это использование таблицы случайных чисел (см. Приложение 5). Таблица случайных чисел заключает в себе цифры от 0 до 9, выбранные случайным образом. Группировки в таблицах применяются исключительно для удобства чтения. При пользовании таблицей в качестве точки отсчета может быть выбрана любая позиция. В зависимости от требований цифры можно выбирать по одной, по две или по три, двигаясь по таблицам вправо или вниз. Случайные числа используются для того, чтобы множеству значений переменной поставить в соответствие множество случайных чисел (например, 0-9, 00-99). Случайные числа ставятся в соответствие значениям переменной пропорционально значениям вероятностей.
Таким образом, из указанных таблиц выбирается случайное число, и переменной присваивается соответствующее значение. Так как в данной задаче значения вероятностей указаны с точностью до двух десятичных знаков, мы будем пользоваться случайными числами, содержащими две цифры. Распределение интервала случайных чисел 00-99 показано на табл. 8.9.
Таблица 8.9
Распределение случайных чисел для интервалов между моментами появления прохожих
| Интервал между появлениями, мин. | Вероятности | Кумулятивные вероятности | Случайные числа |
| 0 | 0,25 0,35 0,18 0,10 0,08 0,04 | 0,25 0,60 0,78 0,88 0,96 1,00 | 00-24 25-59 60-77 78-87 88-95 96-99 |
Если выбирается случайное число 03, то оно принадлежит промежутку (00-24) и характеризует интервал между появлениями прохожих (IAT) в ноль минут. Случайное число 47 принадлежит промежутку (25-59) и соответствует IAT в одну минуту. Используя последовательные случайные числа и двигаясь вдоль по строке или вниз по столбцу таблицы, а также с помощью приведенных выше данных, мы можем поставить в соответствие каждому человеку интервал его появления около интервьюера. Полученные значения IAT накапливаются, начиная с нулевого значения, и в результате позволяют найти время появления каждого прохожего.
Таблица 8.10
Распределение интервалов случайных чисел
для желающих дать интервью
| Согласие прохожего дать интервью | Вероятность | Кумулятивная вероятность | Случайные числа |
| Да Нет | 0,75 0,25 | 0,75 1,00 | 00-74 75-99 |
Чтобы установить, согласится ли моделируемый прохожий дать интервью, выбираем случайное число из другого столбца или строки таблицы. Пусть выбрано число 35. Оно находится в промежутке (00-74). Данный прохожий согласен дать интервью. Если следующее число равно 64, то, поскольку оно принадлежит тому же промежутку, следующий прохожий также даст согласие на интервью.
Таблица 8.11
Распределение интервалов случайных чисел для продолжительности интервью
| Продолжительность интервью, мин | Вероятность | Кумулятивная вероятность | Случайные числа |
| 2 | 0,40 0,45 0,15 | 0,40 0,85 1,00 | 00-39 40-84 85-99 |
Продолжительность интервью устанавливается аналогично, но с использованием отличного от двух предыдущих множества случайных чисел.
Теперь все готово к тому, чтобы начать процесс моделирования. Мы будем продолжать его до тех пор, пока не будет получено 10 интервью. Для каждой переменной выбираются случайные числа, а затем генерируются значения переменных, необходимых для продолжения процесса моделирования (время появления прохожего), а также переменных, необходимых для описания поведения системы (согласие дать интервью и его продолжительность).
Ниже приведены данные из таблиц случайных чисел, которые помогут вам проследить за ходом процесса моделирования.
| 03 35 | 47 64 | 3 16 | 73 22 | 7 94 | 74 39 | 24 84 | 67 42 | 62 17 | 16 53 | 76 31 | 62 63 | 27 01 | 66 63 | 12 78 | 56 59 | 85 33 | 99 21 | 26 12 | 55 34 | 59 29 | 56 57 |
Для интервалов появления прохожего выберем случайные числа с начала списка и будем продвигаться вдоль строки. Данный ряд начинается с чисел 03, 47, 43. Для согласия дать интервью выберем случайные числа второй строки, которая начинается с чисел: 35, 64, 16. Для продолжительности интервью также выберем числа второй строки, но начнем с конца и будем двигаться справа налево:57, 29, 34. Предположим, что моделируемый счетчик времени начинается с нулевого момента. Тогда первый прохожий появится в момент времени, равный О + первый интервал появления прохожего. Предположим также, что каждое следующее интервью может начаться сразу же после окончания предыдущего.
Десятое интервью завершится через 36 мин. после начала процедуры. Использование иного множества случайных чисел приведет к другому результату. Если потребуется определить время, необходимое для десяти интервью, мы должны будем сделать по имитационной модели расчеты для большего числа интервью — например, для 100 или 200. И только после этого можно будет рассчитать среднее время, требуемое для завершения 10 интервью.
Одна из проблем, возникающих при построении имитационных моделей, состоит в том, что необходимо точно знать, какого рода информацию следует собирать, чтобы процесс моделирования можно было продолжить. В данной ситуации небольшой размерности существует возможность идентифицировать каждый шаг и при необходимости вернуться на предыдущий этап, если возникла потребность в дополнительной информации. В ситуациях большего масштаба, моделирование которых осуществляется с помощью компьютеров, очень важно, чтобы решение о том, какие данные необходимы, и о способах их сбора и представления было принято еще на начальном этапе.
Сбор данных преследует две основные цели. Во-первых, их можно использовать при проверке положения о том, что модель функционирует именно так, как и предполагалось при ее составлении. Эта процедура является составной частью обоснования модели. Например, по данным исходного распределения, математическое ожидание продолжительности интервью составит:
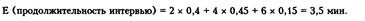
По данным нашей небольшой имитационной модели, на проведение 10 интервью интервьюер затрачивает 28 мин., таким образом, среднее значение продолжительности одного интервью составляет 2,8 мин., что несколько меньше, чем предполагалось изначально. Для выборки такого небольшого размера эта колеблемость неудивительна. Однако если бы мы получили эти же результаты для первых 100 интервью, они означали бы, что модель является некорректной и требует тщательной проверки.
Во-вторых, данные можно использовать для получения некоторой информации непосредственно из модели. Например, сколько времени потребуется, чтобы получить 10 интервью — 36 мин. Какую часть времени интервьюер бездействует? — 8 мин из 36. Сколько человек прошло мимо интервьюера, пока он получал 10 интервью? - 19: 6 человек прошли, пока интервьюер был занят; 3 человека отказались дать интервью; 10 человек были проинтервьюированы.
Данное исследование можно расширить, если, например, ввести в модель второго интервьюера. Затраты на оплату его работы могут быть компенсированы сокращением времени, необходимого для получения 10 интервью.
Введение в модель второго интервьюера требует принятия дополнительных правил, определяющих функционирование модели. Что произойдет, если оба интервьюера будут свободны? Кто из них подойдет к ближайшему следующему прохожему? Примем предпосылку о том, что первого прохожего всегда берет на себя интервьюер 1. Подобные правила необходимо вводить на начальном этапе формулировки любой модели. В данном случае неважно, какой из интервьюеров будет выбран, но при построении всех имитационных
Таблица 8.12
Моделирование процесса проведения 10 интервью
одним интервьювером
| Модель | Согласие | Модель интервью | |||||||
| Номер | появления | дать интервью | |||||||
| прохожего | Случайное | IAT. | Время | Случай ное | Да/нет | Случайное | Продол | Время | |
| число | мин | появления, | число | число | жительность, | ||||
| мин | мин | Начало | Окончание | ||||||
| 0 | О | Да | 0 | ||||||
| Интервьюер | занят | ||||||||
| Интервьюер | занят | ||||||||
| Да | |||||||||
| Да | |||||||||
| Да | |||||||||
| Нет | Отказ | ||||||||
| Нет | Отказ | ||||||||
| Да | |||||||||
| Нет | Отказ | ||||||||
| Да | |||||||||
| Да | |||||||||
| Интервьюер | занят | ||||||||
| Интервьюер | занят | ||||||||
| Да | |||||||||
| Интервьюер | занят | ||||||||
| Интервьюер | занят | ||||||||
| Да | |||||||||
| Да | |||||||||
| 10 интервью набрано |
моделей нужно быть последовательным и уметь четко сформулировать правила функционирования моделируемой системы.
Итак, мы установили, что в данном случае получение 10 интервью займет 27 мин., между тем на практике средние значения вычисляются на основе гораздо более длительного процесса моделирования. Для того чтобы принять решение о том, пользоваться услугами второго интервьюера или нет, потребуются и другие данные, например, о промежутках времени, когда оба интервьюера свободны.
После того как имитационная модель построена, необходимо оценить ее надежность. Мы должны быть уверены в том, что модель воспроизводит формализуемую ситуацию с достаточной степенью точности. Простейший способ оценки надежности состоит в использовании ретроспективных данных и сравнении результатов расчетов, полученных для этих данных по модели, с действительным поведением системы во времени. В приведенном выше примере ретроспективные данные можно не использовать, а оценку надежности модели следует основывать на тщательной проверке и оценке используемых распределений вероятности. Этот момент является очень важным для имитационного моделирования, хотя иногда им пренебрегают.
|
|
|
|
|
Дата добавления: 2014-12-10; Просмотров: 597; Нарушение авторских прав?; Мы поможем в написании вашей работы!