КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Расчет кривой нормального распределения по ординатам нормальной кривой
|
|
|
|
ЗАКОНОМЕРНОСТИ РАСПРЕДЕЛЕНИЯ ЧАСТОТ ВАРИАНТОВ АНТРОПОМЕТРИЧЕСКИХ ПРИЗНАКОВ
Анализ вариационных рядов антропометрических признаков позволяет отметить общую закономерность в распределении численностей, которая заключается в том, что крайние значения размеров тела встречаются значительно реже, чем средние или близкие к ним значения.
Для решения задач антропометрической стандартизации необходимо обобщить повседневные наблюдения и выразить эту закономерность в количественной форме, т. е. изучить, сколько и каких вариантов величин каждого признака встречается во всей совокупности, и научиться предсказывать эти цифры на основе изучения ограниченной выборки.
Область математики, которая с помощью формул (или математических моделей) дает возможность описывать и сопоставлять ряды распределения частот, носит название теории вероятностей.
Понятию «частота встречаемости признака» в математике соответствует понятие «вероятности» (под вероятностью понимается возможность проявления того или иного события).
Теория вероятностей, основываясь на данных, полученных на практике, создает такие теоретические распределения частот или вероятностей, которые служат для описания реально встречающихся в природе распределений. Одним из таких распределений является нормальное распределение.
Нормальное распределение отображает сложность и многообразие условий, влияющих на изменчивость признаков. Основные свойства нормального распределения следующие:
1) на величину признаков влияет множество факторов (например, длина тела человека зависит как от наследственных факторов, так и от условий, в которых протекает рост и развитие организма в отдельные возрастные периоды);
2) степень влияния каждого отдельного фактора невелика;
3) действия всех факторов суммируются;
4) влияние многочисленных и независимых друг от друга факторов при совокупном действии приводит к нормальному распределению.
Нормальное распределение охватывает широкий круг явлений как в природе, так и в технике * [3-6; 15].
Еще во второй половине прошлого столетия бельгийский антрополог А. Кетле (1796-1874 г.) заметил применимость закона нормального распределения к антропометрическим признакам. По отношению к ним закон нормального распределения может быть сформулирован так: различные варианты признаков в любой неподобранной группе населения одного пола и возраста встречаются с различной частотой — средние и близкие к ним значения встречаются наиболее часто, по мере удаления от средней арифметической величины частота встречаемости признака уменьшается [1; 5; 6; 15].
Таким образом, нормальное распределение представляет собой определенную функциональную зависимость между величиной признака и его частотой в совокупности. Эта зависимость, как и многие функциональные зависимости между двумя переменными, может быть выражена в табличной форме, графически и при помощи формулы.
Графически закон нормального распределения выражается симметричной, одновершинной плавной кривой, называемой кривой нормального распределения, или просто нормальной кривой**.
Уравнение нормальной кривой имеет вид
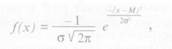
где f(x) — частота встречаемости признака (относительная численность); М — средняя арифметическая величина: σ и σ2— среднее квадратичное отклонение и дисперсия признака, характеризующие степень его изменчивости;,\' — переменное значение признака; е — основание натурального логарифма, равное 2,71828; к — постоянное число, равное 3,14159.
Если принять σ = 1 и вместо
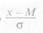
подставить и, то уравнение нормальной кривой примет вид
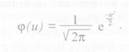
В таком виде уравнение носит название функции нормированного отклонения φ (и), которую можно рассчитать для любых значений и.
Таблицы значения φ (и) обычно называются таблицами ординат кривой нормального распределения.
Исходя из уравнений кривой нормального распределения и зная, чему равна средняя арифметическая величина и среднее квадратичное отклонение, по таблицам ординат можно рассчитать теоретическую кривую нормального распределения для любого эмпирического ряда. Чтобы пользоваться таблицами, необходимо выразить значение признака в виде отклонений от средних арифметических величин, деленных на свои средние квадратичные отклонения:
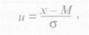
где и — нормированное отклонение; х - М — отклонение середины значений классовых интервалов от средней арифметической величины; σ — среднее квадратичное отклонение.
Такая операция называется нормированием.
Кривую нормального распределения рассчитывают следующим образом:
1) находят отклонения среднего значения каждого классового интервала от средней арифметической величины (х — М)\
2) вычисляют нормированные отклонения для каждого классового интервала;
3) по таблицам ординат нормальной кривой (см. приложение 3) находят φ (и) (с округлением до четвертого знака);
4) теоретическую численность находят по формуле
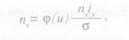
где п1 — эмпирическая; f — классовый интервал.
Допустим, что надо рассчитать теоретическую кривую нормального распределения для эмпирического вариационного ряда по длине тела женщин.
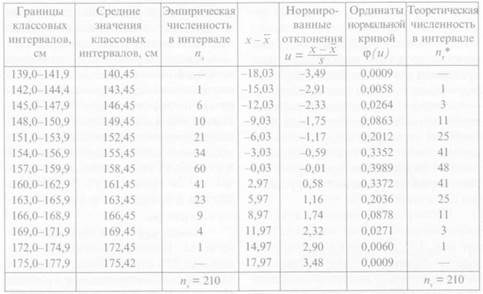
Средняя арифметическая величина для данного вариационного ряда М = x-=158,42 см, среднее квадратичное отклонение σ = s = 5,16 см, численность n - 210, классовый интервал ix = 3 см. Расчет кривой нормального распределения представлен в табл. 3.6.
После расчета эмпирическую б и теоретическую а кривые наносят на график (рис. 3.3). где по оси абсцисс откладывают абсолютные значения признака от минимума до максимума (средние значения классовых интервалов), по оси ординат — частоту встречаемости ири-шака. Из графика видно, что теоретическая кривая а расположена симметрично относительно вертикали, проведенной через среднюю арифметическую величину. Средняя арифметическая величина, медиана и мода в кривой нормального распределения совпадают (рис. 3.4).
Ветви кривой асимптотически приближаются к оси абсцисс.
Как видно из формулы, в нормальном распределении между средним квадратичным отклонением о и частотой встречаемости вариантов признака в совокупности имеется функциональная зависимость. Эта зависимость позволяет определить относительную численность случаев, заключенных в любом заданном интервале значений признака. Для этого достаточно знать среднее арифметическое значение признака в данной совокупности и его среднее квадратичное отклонение. Вычислив нормированные отклонения заданных границ интервала от средней арифметической величины М, по таблицам площадей (интегралов) нормальной кривой можно определить относительные численности, заключенные в заданных границах.
Для примера выпишем из таблиц площадей (см. приложение 4) несколько соотношений, которые можно изобразить и графически (рис. 3.5). Оказывается, что при нормальном распределении признака в пределах М ± 0,67 σ укладывается 50% случаев в пределах М ± 1 σ — 68,27% (см. рис 3.5, и). В пределах М ± 2 σ заключено 95,45% (см. рис. 3.5, б) и в пределах М ± З σ — 99,73% случаев (см. рис. 3.5, в).
Можно записать и обратные соотношения. Например, можно утверждать, что 95% случаев лежит в пределах М ±1. 96 σ 99% случаев — в пределах •М ± 2,58 σ и 99,9% случаев — в пределах М ± 3.29 σ. Практически вся совокупность заключена в пределах М ± 3,5а. Значения признаков, выходящие за эти пределы (при наличии нормального распределения), следует считать нетипичными для данной совокупности (см. приложение 4).
Таблица 3.6
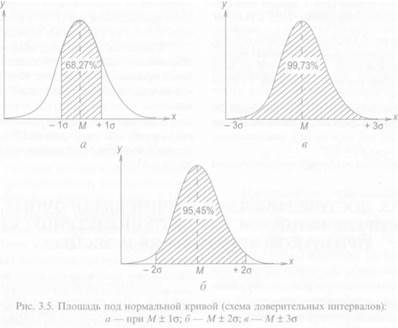
В математической статистике при оценке результатов измерений принято пользоваться определенными частями площади кривой нормального распределения, а именно: 95, 99, 99,9%. Вероятности 0,95, 0,99 и 0,999 получили название доверительных вероятностей*. Каждая из этих вероятностей соответствует определенным границам, а именно: М± 1,96 σ, М± 2,58 σи М+ 3,29 σ соответственно. Интервалы, заключенные в этих пределах, называются доверительными интервалами для среднего значения признака. Доверительный интервал показывает границы, в которых с той или иной вероятностью заключена искомая величина4 [3].
Например, если средний рост мужчин 167 см, среднее квадратичное отклонение 6 см, то можно утверждать с вероятностью 0,99, что у первого встреченного нами человека рост будет не ниже 151,5 см и не выше 182,5 см, так как 167-(6-2,58 σ )=151,52 см и 167+(6-2,58 σ )=182,48 см.
Разберем несколько примеров применения закона нормального распределения антропометрических признаков для решения конкретных задач.
Пример 1. Средняя арифметическая величина длины тела для группы мужчин М = х = 168 см, среднее квадратичное отклонение σ = s = 5 см.
Определить, в каких пределах заключено 45, 86,6 и 99,95% случаев этой совокупности.
В приложении 4 находим, что 45% всех случаев находится в пределах М ± 0,6 σ. Следовательно, х ± 0,6 • 5 = (168 ±3) см, т. е. 45% людей в данной совокупности имеют длину тела от 165 до 171 см; 86,6% — в пределах М ± 1,5 σ, т. е. 86,6% людей в данной совокупности имеют длину тела от 160,5 до 175,5 см; и, наконец, 99,95% — в пределах М ± 3,5 σ, т. е. минимальным и максимальным значениями длины тела в данной совокупности будут соответственно 151.5 и 184,5 см.
Пример 2. Определить, какова относительная численность людей в данной выборке с обхватом груди от 100 до 104 см, если средняя арифметическая величина х =96 см и s = 4 см.
Минимальное изданных значений (100 см) отстоит от средней арифметической величины (96 см) на 4 см (d1, максимальное (104 см) —на 8 см (d2).
В пределах от средней арифметической величины до минимального значения признака укладывается +lσ (s:d1) в нашем примере 4: 4 = +1σ), или 34,1% случаев.
В пределах от средней арифметической величины до максимального заданного значения признака укладывается +2σ (s: d2, в нашем примере 8:4 = +2σ), или 47,7% случаев.
Следовательно, относительная численность людей с обхватом груди от 100 до 104 см в данной выборке будет составлять 47,7% -34,1% = 13,6%.
|
|
|
|
|
Дата добавления: 2015-06-04; Просмотров: 3160; Нарушение авторских прав?; Мы поможем в написании вашей работы!