КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методы статистического описания результатов наблюдений 1 страница
|
|
|
|
Элементы математической статистики.
9.1. Основные задачи математической статистики
Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных - результатов наблюдений.
Первая задача математической статистики - указать способы сбора и группировки статистических сведений, полученных в результате наблюдений или в результате специально поставленных экспериментов.
Вторая задача математической статистики - разработать методы анализа статистических данных в зависимости от целей исследования. Здесь:
а) оценка неизвестной вероятности события; оценка параметров распределения, вид которого известен; оценка зависимости случайной величины и др.;
б) проверка статистических гипотез о виде неизвестного распределения или о величине параметров распределения, вид которого известен.
Современная математическая статистика разрабатывает способы определения числа необходимых испытаний до начала исследования (планирование эксперимента), в ходе исследования (последовательный анализ), и решает многие задачи. Математическая статистика определяется как наука о принятии решений в условиях неопределенности.
Задачи математической статистики помогают создавать методы сбора и обработки статистических данных для получения научных и практических выводов.
9.2. Выборка, способы её представления.
Математическая статистика позволяет получать обоснованные выводы о параметрах, видах распределений и других свойствах случайных величин по конечной совокупности наблюдений над ними - выборке.
В практике статистических наблюдений различают два вида наблюдений: сплошное (изучаются все объекты совокупности) и несплошное, выборочное (изучается часть объектов).
Вся подлежащая изучению совокупность объектов (наблюдений) называется генеральной совокупностью.
Понятие генеральной совокупности в определенном смысле аналогично понятию случайной величины (закону распределения вероятностей, вероятностному пространству), так как полностью обусловлено определенным комплексом условий.
Часть объектов, отобранная для непосредственного изученияиз генеральной совокупности, называется выборочной совокупностью, или выборкой. Числа объектов (наблюдений) в генеральной или выборочной совокупности называются их объемами. Генеральная совокупность может иметь как конечный, так и бесконечный объем.
Сущность выборочного метода состоит в том, чтобы по некоторой части генеральной совокупности (по выборке) выносить суждение о её свойствах в целом.
Преимущество выборочного метода по сравнению со сплошным состоит в следующем:
- позволяет экономить затраты ресурсов;
- является единственно возможным в случае бесконечной генеральной совокупности или в случае, когда исследование связано с уничтожением наблюдаемых объектов;
- дает возможность углубленного исследования за счет расширения программы исследования;
- позволяет снизить ошибки регистрации, т.е. расхождение между истинным и зарегистрированным значениями признака.
 Основной недостаток выборочного метода - ошибки исследования, называемые ошибками репрезентативности (представительства).
Основной недостаток выборочного метода - ошибки исследования, называемые ошибками репрезентативности (представительства).
Различают следующие виды выборок:
- собственно-случайная выборка, образованная случайным выбором элементов без расчленения на части или группы;
- механическая выборка, в неё элементы из генеральной совокупности отбираются через определенный интервал;
- типическая (стратифицированная) выборка, в которую случайным образом отбираются элементы из типических групп;
- серийная (гнездовая) выборка, в которую случайным образом отбираются не элементы, а целые группы совокупности, причем сами серии подвергаются сплошному наблюдению.
Используют два способа образования выборки:
- повторный отбор (по схеме возвращенного шара), когда каждый элемент, случайно отобранный и обследованный, возвращается в общую совокупность и может быть повторно отобран;
- бесповторный отбор (по схеме невозвращенного шара), когда отобранный элемент не возвращается в общую совокупность.
Итак, закон распределения некоторой случайной величины X называется распределением генеральной совокупности, а случайный вектор (X1,...,Xn) - выборочным вектором. Числа х1,..., хп, получаемые на практике при n -кратном повторении некоторого эксперимента в неизменных условиях, представляют собой реализацию выборочного вектора и есть выборка (х1,х2,...,хп) объема п.
Выборку (х1,х2,...,хп) при необходимости можно рассматривать как точку выборочного пространства, т. е. множества, на котором задано распределение выборочного вектора (Х1,Х2,...,Хn).
Аналогично определяется выборка в случае, когда некоторый случайный эксперимент связан с несколькими случайными величинами. Так, выборка объема п из двумерной генеральной совокупности есть последовательность (х1, у1),...,(хn,уn) пар значений случайных величин X и Y, принимаемых ими в п независимых повторениях некоторого случайного эксперимента.
Вариационным рядом выборки х1,х2,...,хп называется способ ее записи, при котором элементы упорядочиваются по величине, т е. записываются в виде последовательности х (1), х (2),…, х(n), где х(1)≤х(2)≤...≤х(n).
Разность между максимальным и минимальным элементами выборки x (max) - x (min) =ωназывается размахом выборки. Пусть выборка (х1,х2,...,хп) содержит k различных чисел z1,z2,...,zk, причем zi встречается ni раз (i = 1,2, ...,k). Число ni называют частотой элемента выборки zi. Следует заметить, что 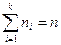 .
.
Статистическим рядом называют последовательность пар (zi,ni). Статистический ряд записывают в виде таблицы, в первой строке которой находятся элементы zi, а во второй - их частоты.
Пример 28. Записать в виде вариационного и статистического рядов выборку 5, 3, 7, 10, 5, 5, 2, 10, 7, 2, 7, 7, 4, 2, 4. Определить размах выборки.
Решение. В данном случае объем выборки n = 15. Упорядочим элементы выборки по величине, получим вариационный ряд 2, 2, 3, 4, 4, 5, 5, 5, 7, 7, 7, 7, 10, 10. Найдем размах выборки ω=10-2= 8. Различными в заданной выборке являются элементы z1 = 2, z2 =3, z3 = 4, z4 = 5, z5 = 7, z6 = 10; их частоты соответственно равны n1 = 3, n2 =1, n3 = 2, n4 = 3, n5 = 4, n6 = 2. Статистический ряд исходной выборки можно записать в виде следующей таблицы:
| zi | ||||||
| ni |
Для контроля правильности записи находим 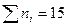 . При большом объеме выборки ее элементы рекомендуется объединять в группы (разряды), представляя результаты опытов в виде группированного статистического ряда. В этом случае интервал, содержащий все элементы выборки, разбивается на k непересекающихся интервалов. Вычисления упрощаются, если эти интервалы имеют одинаковую длину
. При большом объеме выборки ее элементы рекомендуется объединять в группы (разряды), представляя результаты опытов в виде группированного статистического ряда. В этом случае интервал, содержащий все элементы выборки, разбивается на k непересекающихся интервалов. Вычисления упрощаются, если эти интервалы имеют одинаковую длину 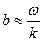 . В дальнейшем рассматривается именно этот случай. После того как частичные интервалы выбраны, определяют частоты - количество ni элементов выборки, попавших в i -й интервал (элемент, совпадающий с верхней границей интервала, относится к следующему интервалу). Получающийся статистический ряд в верхней строке содержит середины zi интервалов группировки, а в нижней — частоты ni (i = 1,2,..., k).
. В дальнейшем рассматривается именно этот случай. После того как частичные интервалы выбраны, определяют частоты - количество ni элементов выборки, попавших в i -й интервал (элемент, совпадающий с верхней границей интервала, относится к следующему интервалу). Получающийся статистический ряд в верхней строке содержит середины zi интервалов группировки, а в нижней — частоты ni (i = 1,2,..., k).
Наряду с частотами одновременно подсчитываются также накопленные частоты 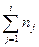 , относительные частоты ni /п и накопленные относительные частоты
, относительные частоты ni /п и накопленные относительные частоты 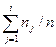 , i = 1,2,..., k. Полученные результаты сводятся в таблицу, называемую таблицей частот группированной выборки.
, i = 1,2,..., k. Полученные результаты сводятся в таблицу, называемую таблицей частот группированной выборки.
Следует помнить, что группировка выборки вносит погрешность в дальнейшие вычисления, которая растет с уменьшением числа интервалов.
Пример 29. Представить выборку 55 наблюдений в виде таблицы частот, разбив имеющиеся данные выборки на семь интервалов группировки. Выборка:
| 20,3 | 15,4 | 17,2 | 19,2 | 23,3 | 18,1 | 21,9 |
| 15,3 | 16,8 | 13,2 | 20,4 | 16,5 | 19,7 | 20,5 |
| 14,3 | 20,1 | 16,8 | 14,7 | 20,8 | 19,5 | 15,3 |
| 19,3 | 17,8 | 16,2 | 15,7 | 22,8 | 21,9 | 12,5 |
| 10,1 | 21,1 | 18,3 | 14,7 | 14,5 | 18,1 | 18,4 |
| 13,9 | 19,1 | 18,5 | 20,2 | 23,8 | 16,7 | 20,4 |
| 19,5 | 17,2 | 19,6 | 17,8 | 21,3 | 17,5 | 19,4 |
| 17,8 | 13,5 | 17,8 | 11,8 | 18,6 | 19,1 |
В данном случае размах выборки ω =23,8 -10,1 = 13,7; тогда длина интервала группировки будет b = 13,7/7≈2. В качестве первого интервала возьмем интервал 10 - 12. Результаты группировки сведем в таблицу 1
Таблица 1
| Номер интервала i | Границы интервала | Середина интервала zi | Частота ni | Накопленная частота
| Относительная частота ni /п | Накопленная
относительная
частота
|
| 10-12 | 2 | 0,0364 | 0 0364 | |||
| 12-14 | 0,0727 | 0 1091 | ||||
| 14-16 | 0,1455 | 0 2546 | ||||
| 16-18 | 0,2182 | 0,4728 | ||||
| 18-20 | 0,2909 | 0 7637 | ||||
| 20-22 | 0,1818 | 0,9455 | ||||
| 22-24 | 0,0545 | 1,0000 |
9.3. Функция распределения.
Пусть (х1,х2,...,хп) - выборка из генеральной совокупности с функцией распределения Fx(x). Распределением выборки называется распределение дискретной случайной величины, принимающей значения х1,х2,...,хп с вероятностями 1/ n. Соответствующую функцию распределения называют эмпирической (выборочной) функцией распределения и обозначают 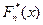 .
.
Эмпирическую функцию распределения определим по значениям накопленных частот соотношением 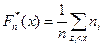 , здесь суммируются частоты тех элементов выборки, для которых выполняется неравенство zi < х. Тогда получим, что
, здесь суммируются частоты тех элементов выборки, для которых выполняется неравенство zi < х. Тогда получим, что 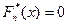 при х≤х(1) и
при х≤х(1) и 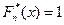 при х>х(n). На промежутке (х(1); х(n) ] представляет собой неубывающую кусочно-постоянную функцию.
при х>х(n). На промежутке (х(1); х(n) ] представляет собой неубывающую кусочно-постоянную функцию.
Аналогично определяем эмпирическую функцию распределения для группированной выборки.
Значение эмпирической функции распределения для статистики определяется следующим утверждением.
Теорема (Гливенко). Пусть - эмпирическая функция распределения, построенная по выборке объема п из генеральной совокупности с функцией распределения Fx(x). Тогда для любого х Î (- ∞,+∞) и любого ε > 0
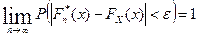 .
.
Таким образом, при каждом х сходится по вероятности к Fx(x) и при большом объеме выборки может служить приближенным значением (оценкой) функции распределения генеральной совокупности в каждой точке х.
9.4. Гистограмма и полигон.
Для наглядного представления выборки можно использовать гистограмму и полигон частот.
Гистограммой частот группированной выборки называется кусочно-постоянная функция, постоянная на интервалах группировки и принимающая на каждом из них значения 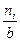 ,
,
i = 1,2,..., k соответственно. Площадь ступенчатой фигуры под графиком гистограммы равна объему выборки п.
Аналогично определяется гистограмма относительных частот. Площадь соответствующей ступенчатой фигуры для нее равна единице.
При увеличении объема выборки и уменьшении интервала группировки гистограмма относительных частот является статистическим аналогом плотности распределения fx(x) генеральной совокупности.
Полигоном частот называется ломаная с вершинами в точках 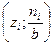 , где i = 1,2,..., k, а полигоном относительных частот - ломаная с вершинами в точках
, где i = 1,2,..., k, а полигоном относительных частот - ломаная с вершинами в точках 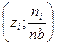 , где i = 1,2,..., k. Имеем, что полигон относительных частот получается из полигона частот сжатием по оси Оу в п раз.
, где i = 1,2,..., k. Имеем, что полигон относительных частот получается из полигона частот сжатием по оси Оу в п раз.
Если плотность распределения генеральной совокупности является достаточно гладкой функцией, то полигон относительных частот является более хорошим приближением плотности, чем гистограмма.
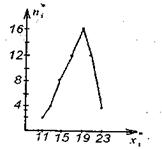
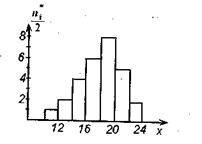
Пример 30. Построить гистограмму и полигон частот, а также график эмпирической функции распределения группированной выборки из примера 29.
Решение. По результатам группировки (см. таблицу 1.) строим гистограмму частот (рис. 7). Соединяя отрезками ломаной середины верхних оснований прямоугольников, из которых состоит полученная гистограмма, получаем соответствующий полигон частот (рис. 8).
 Так как середина первого интервала группировки z1 = 11, то при х ≤ 11. Рассуждая аналогично, находим, что при х > 23. На полуинтервале (11,23] эмпирическую функцию распределения строим по данным третьего и последнего столбцов таблицы 1.
Так как середина первого интервала группировки z1 = 11, то при х ≤ 11. Рассуждая аналогично, находим, что при х > 23. На полуинтервале (11,23] эмпирическую функцию распределения строим по данным третьего и последнего столбцов таблицы 1.
Рис.7 Рис.8
имеет скачки в точках, соответствующих серединам интервалов группировки. В результате получаем график , изображенный на рис. 9.
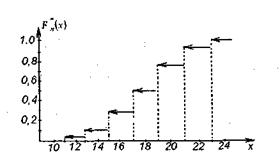
Рис.9
9.5. Метод моделирования.
В задачах статистического анализа сложных систем, например, при разработке систем автоматического проектирования (САПР), широко используется метод моделирования выборки из генеральной совокупности с заданным законом распределения.
Пусть случайная величина X имеет функцию распределения Fx (x). Как известно из теории вероятностей случайная величина Y = Fx(x) имеет равномерное распределение R (0,l). Отсюда следует, что случайная величина X может быть получена из равномерно распределенной случайной величины Y по формуле 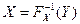 , где
, где 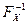 - функция, обратная к Fx (заведомо существующая для случайных величин непрерывного типа).
- функция, обратная к Fx (заведомо существующая для случайных величин непрерывного типа).
Метод моделирования выборки из генеральной совокупности с законом распределения Fx(x) реализуется следующим алгоритмом: 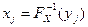 , j = 1,2,..., n, где у1, у2,..., уn - выборка из
, j = 1,2,..., n, где у1, у2,..., уn - выборка из
генеральной совокупности с равномерным распределением R (0,1), являющаяся последовательностью случайных чисел.
Случайные числа у1, у2,..., уn можно получить, выбрав случайным образом n чисел из таблицы- приложений П12 (см. в конце учебного пособия) и разделив каждое выбранное число на 100. При наличии любого вычислительного устройства случайные числа у1, у2,..., уn генерируются с помощью формулы 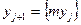 , jÎN, где {а} - дробная часть числа a, a m- простое число, большее десяти. В качестве начального значения у1 в записанной выше формуле можно выбрать произвольное число из интервала (0,l) с ненулевыми разрядами в десятичной системе счисления. От удачного выбора начального значения ух зависит качество последовательности у1, у2,..., уn.
, jÎN, где {а} - дробная часть числа a, a m- простое число, большее десяти. В качестве начального значения у1 в записанной выше формуле можно выбрать произвольное число из интервала (0,l) с ненулевыми разрядами в десятичной системе счисления. От удачного выбора начального значения ух зависит качество последовательности у1, у2,..., уn.
Этот алгоритм получения выборки из генеральной совокупности с законом распределения Fx(x) поясняется на рис. 10.
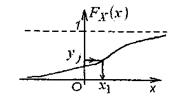
Рис. 10.
Для получения выборки из генеральной совокупности, распределенной по закону N (0,1), можно воспользоваться алгоритмом, основанным на любом из следующих соотношений:
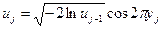 , j = 2,3,..., n,
, j = 2,3,..., n,
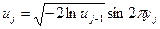 ,
,
где, как и выше, у1,у2,...,уп - выборка из генеральной совокупности с равномерным распределением R (0,1).
9.6. Числовые характеристики выборочного распределения.
Пусть х1,х2,...,хп -выборка объема п из генеральной совокупности с функцией распределения Fx(x). Рассмотрим выборочное распределение, т. е. распределение дискретной случайной величины, принимающей значения х1,х2,...,хп с вероятностями, равными 1 /п. Числовые характеристики этого выборочного распределения называются выборочными (эмпирическими) числовыми характеристиками. Следует отметить, что выборочные числовые характеристики являются характеристиками данной выборки, но не являются характеристиками распределения генеральной совокупности. Чтобы подчеркнуть это различие, выборочные характеристики в дальнейшем будем обозначать теми же символами, что и случайные величины, но со значком * наверху. Некоторые выборочные характеристики имеют традиционные обозначения, например,  - выборочное среднее.
- выборочное среднее.
Пример 31. Найти формулы, определяющие выборочные математическое ожидание и дисперсию для негруппированной выборки объема п.
Решение. Математическое ожидание дискретной случайной величины определяется по формуле
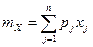 .
.
Так как для выборочного распределения рj = 1/ n, то 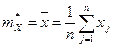 .
.
Аналогично будем иметь выборочную дисперсию 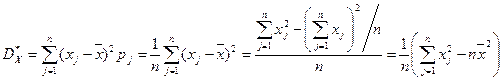 .
.
Выборочной модой 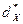 унимодального (одновершинного) распределения называется элемент выборки, встречающийся с наибольшей частотой.
унимодального (одновершинного) распределения называется элемент выборки, встречающийся с наибольшей частотой.
Выборочной медианой называется число 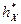 , которое делит вариационный ряд на две части, содержащие равное число элементов.
, которое делит вариационный ряд на две части, содержащие равное число элементов.
Если объем выборки п — нечетное число (т.е. п = 2l +1), то 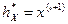 , то есть является элементом вариационного ряда со средним номером. Если же п = 2 l, то
, то есть является элементом вариационного ряда со средним номером. Если же п = 2 l, то 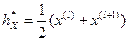 .
.
Пример 32. Определить среднее, моду и медиану для выборки 5, 6, 8, 2, 3, 1, 1, 4.
Решение. Представим данные в виде вариационного ряда: 1, 1, 2, 3, 4, 5, 6,8. Выборочное среднее 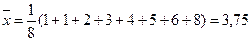 . Все элементы входят в выборку по одному разу, кроме 1, следовательно, мода
. Все элементы входят в выборку по одному разу, кроме 1, следовательно, мода 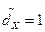 . Так как п = 8, то медиана
. Так как п = 8, то медиана 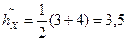 .
.
Итак, 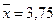 , ,
, , 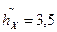 .
.
Для упрощения вычислений выборочных среднего и дисперсии группированной выборки, эту выборку преобразуют так: 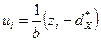 , i= 1,2,..., k,где - выборочная мода, а b - длина интервала группировки. Эти соотношения показывают, что в выборку z1 ,z2,...,zn внесена систематическая ошибка , а результат подвергнут преобразованию масштаба с коэффициентом k = 1/b. Полученный в результате набор чисел u1 ,u2,...,un можно рассматривать как выборку из генеральной совокупности
, i= 1,2,..., k,где - выборочная мода, а b - длина интервала группировки. Эти соотношения показывают, что в выборку z1 ,z2,...,zn внесена систематическая ошибка , а результат подвергнут преобразованию масштаба с коэффициентом k = 1/b. Полученный в результате набор чисел u1 ,u2,...,un можно рассматривать как выборку из генеральной совокупности 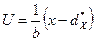 . Тогда выборочные среднее и дисперсия
. Тогда выборочные среднее и дисперсия  исходных данных связаны со средним
исходных данных связаны со средним 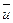 и дисперсией
и дисперсией 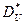 преобразованных данных следующими соотношениями:
преобразованных данных следующими соотношениями: 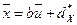 ,
, 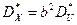 .
.
Пример 33. Вычислить среднее и дисперсию группированной выборки
| Границы интервалов | 134-138 | 138-142 | 142-146 | 146-150 | 150-154 | 154-158 |
| Частоты |
Решение. Длина интервала группировки b = 4, значение середины интервала, встречающегося с наибольшей частотой 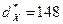 . Преобразование последовательности середин интервалов выполняется по формуле:
. Преобразование последовательности середин интервалов выполняется по формуле:
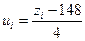 , где i = 1,2,...,6.
, где i = 1,2,...,6.
Таблица 2
| i | zi | ui | ni | ni ui | ni ui2 | ni (ui +1)2 |
| -3 | -3 | |||||
| -2 | -6 | |||||
| -1 | -15 | |||||
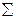
| - | - | -6 |
Вычисления сведены в таблицу 2. Последний столбец этой таблицы служит для контроля вычислений при помощи тождества 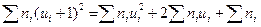 .
.
Выполняя вычисления, получим 58 + 2 · (-6) + 23 = 99.
Полученный результат показывает, что вычисления выполнены правильно. По формулам, данным выше, находим средние значения U
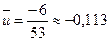 ,
, 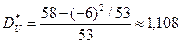 .
.
Далее находим средние данной выборки:
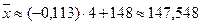 ,
, 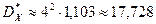 .
.
9.7. Выборочные коэффициенты асимметрии, эксцесса. Квантиль.
Выборочные коэффициенты асимметрии и эксцесса вычисляются по формулам  ,
, 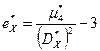 .
.
Вычисление выборочных коэффициентов асимметрии и эксцесса для группированной выборки значительно упрощается, если данные предварительно преобразовать. При этом используют следующие формулы:
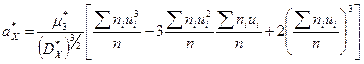 ,
,
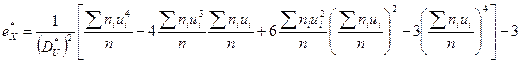 .
.
Для контроля подсчета сумм 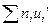 , l = 1,2,3,4 вычисляют отдельно правую и левую части тождества
, l = 1,2,3,4 вычисляют отдельно правую и левую части тождества 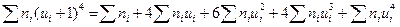 . Результаты вычислений следует оформить в виде таблицы.
. Результаты вычислений следует оформить в виде таблицы.
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 4042; Нарушение авторских прав?; Мы поможем в написании вашей работы!